SS-1
Project Breakdown: SS-1 Signal Shell
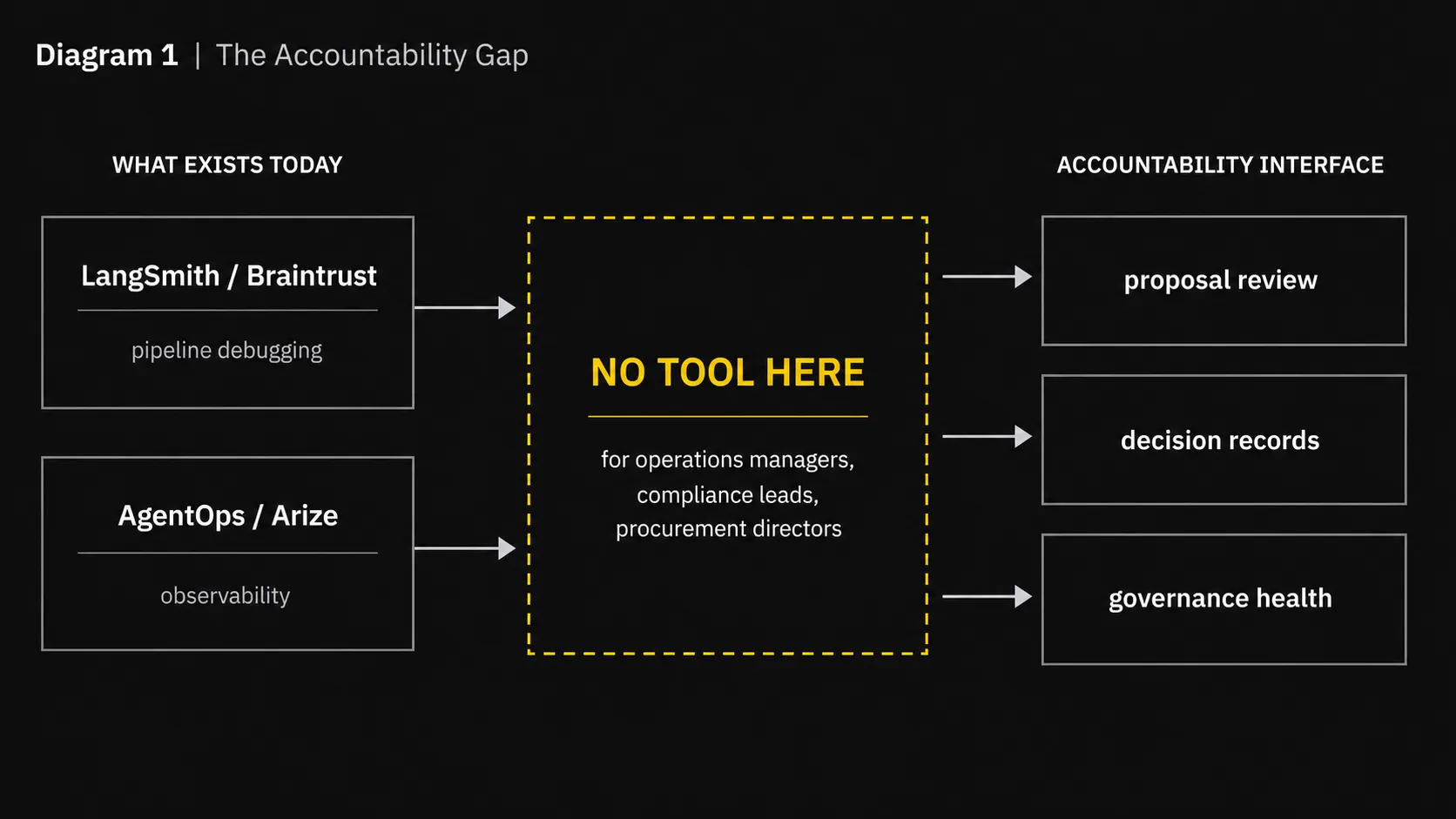
SS-1 Signal Shell is a market intelligence engine for product teams. It monitors competitor changes, filters noise, generates structured strategy briefs and asks a human to approve any update to the product's strategic record. The project explores how AI can support competitive judgement without turning every external signal into a reactive backlog item.