Key takeaways in 3 minutes
A proprietary model is not automatically a moat. For many AI products, the more practical asset is a learning loop.
Do not start by claiming you own the intelligence. Build the mechanism that earns it.
The question is not "should we train our own model?" The better question is: what will our product learn that nobody else can see?
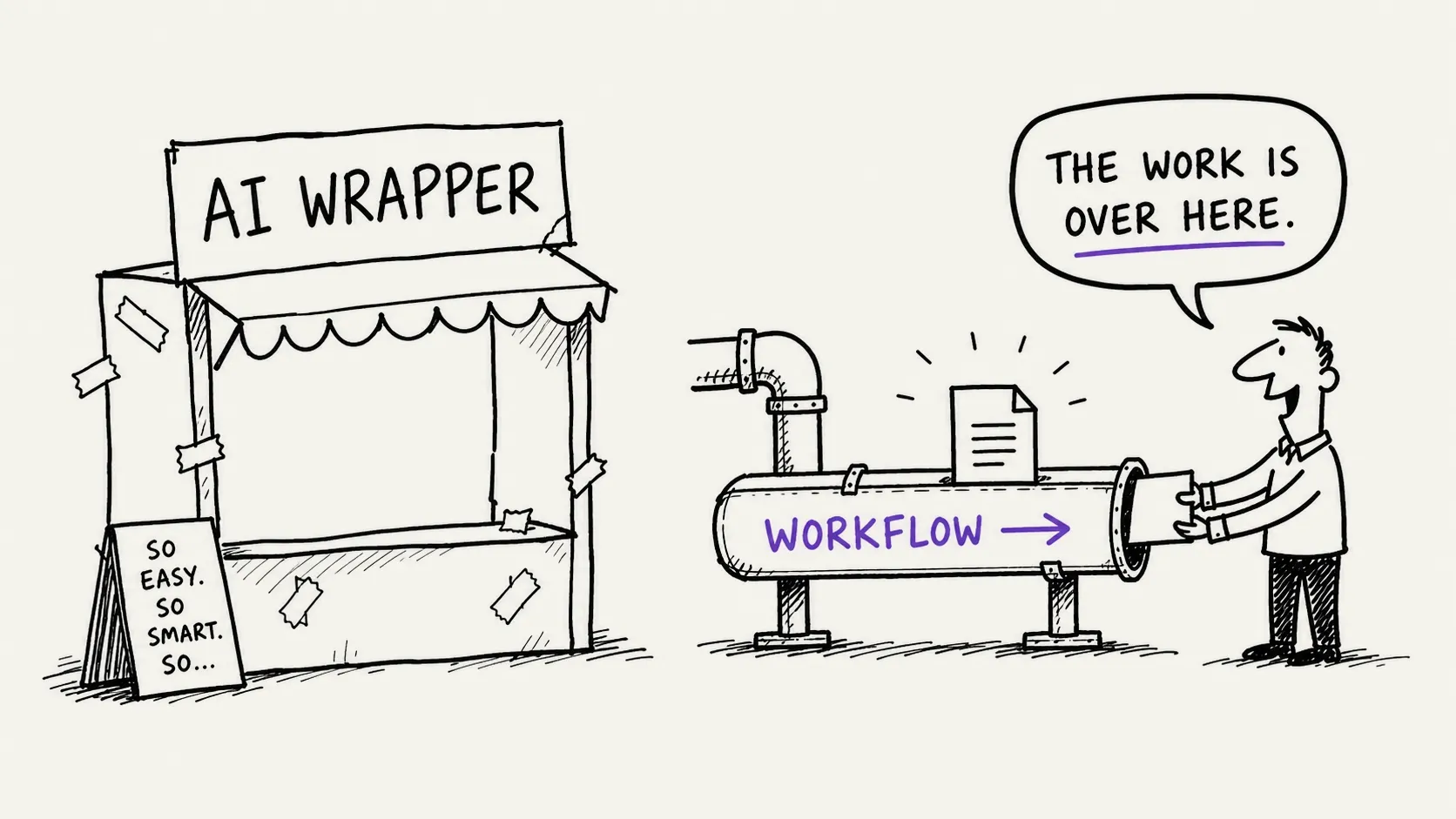
A model without a learning loop is just an expensive opinion machine with a nicer API.
That is a less glamorous question, admittedly. "We have a proprietary model" sounds much more serious in a pitch deck. It has the right kind of boardroom weight. It suggests intellectual property, defensibility, technical depth and perhaps a graph with an upward arrow.
But a model without a learning loop is just an expensive opinion machine with a nicer API.
For many AI products, especially early ones, the defensible asset is not the model. It is the mechanism that turns real use into structured improvement: corrections, approvals, rejections, escalations, outcomes, edge cases and customer-specific rules.
Own that loop, and you may eventually have a reason to build or tune a specialist model. Skip the loop, and you may simply have a very costly way to produce plausible answers.
Why "Our Own Model" Sounds So Attractive
It is easy to see why teams jump to model ownership. Foundation models are powerful, but they are also broadly available. If everyone can access similar capability, leaders naturally ask where advantage comes from.
"We will build our own model" feels like an answer.
Sometimes it is. In the right context, specialist models can be valuable. They can improve accuracy, reduce cost, support compliance requirements, adapt to domain language, or outperform general models on narrow tasks.
But building a model too early can be expensive theatre. Without proprietary data, clear evaluation benchmarks, workflow context and enough real corrections, the team may not know what the model needs to be good at. It is like ordering a custom suit before deciding whether you need a dinner jacket, a raincoat or something that can survive a warehouse visit.
The first job is not to own the model. The first job is to own the learning.
What A Learning Loop Is
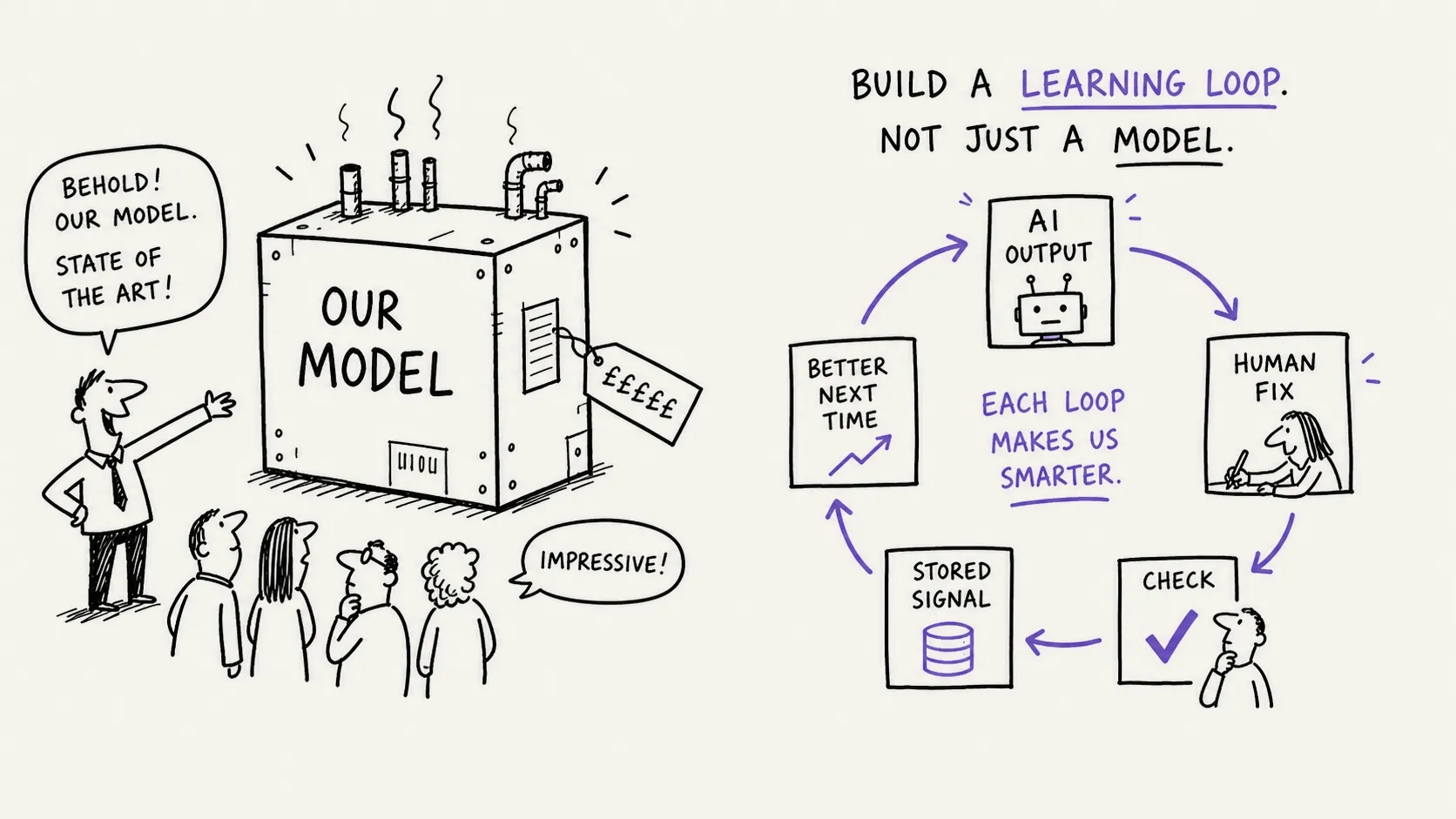
A learning loop is the product design that captures what happens when AI meets real work.
The system produces an output. A human reviews it. They approve, correct, reject, escalate or override it. The product captures that action as structured information. The system uses the signal to improve prompts, retrieval, rules, evaluations, workflow logic or, later, a specialist model.
The key word is structured.
If users fix AI output manually and the product learns nothing, the intelligence is leaking out through the floorboards. The organisation may get the immediate task done, but the product does not become smarter.
A useful learning loop asks: what kind of correction was this? Was it factual, formatting, policy, tone, classification, routing, priority, missing evidence, or customer-specific rule? Was this a one-off edit, or something that should affect future behaviour?
That distinction is where defensibility begins.
Corrections are product intelligence.
Corrections Are Product Intelligence
Human corrections can look like friction. In a good AI product, they are also data.
When a finance user fixes an extracted supplier name, they may reveal a matching rule. When a claims handler overrides a recommendation, they may reveal an exception. When a compliance reviewer rejects an AI summary, they may reveal missing evidence. When a support manager changes a classification, they may reveal how the organisation actually thinks about urgency.
These moments are easy to waste. Many products let users correct the result but fail to preserve the lesson.
That is a design failure as much as a technical one. The correction experience needs to be fast enough that users will actually do it, but structured enough that the product can learn. Nobody wants to become an unpaid data janitor because the AI needed a hobby.
Good product architecture makes the correction useful without making the user feel punished for helping.
Evaluation Comes Before Specialisation
A learning loop also gives the team something most premature model strategies lack: a way to measure improvement.
Before training or fine-tuning anything, the team needs to know what better means. Better extraction accuracy? Fewer escalations? Faster approval? Higher confidence? Reduced rework? Better compliance coverage? More consistent routing?
Without evaluation, a custom model can become a ceremonial object. Expensive, impressive and oddly difficult to challenge.
The loop creates the evidence base. It gives you real examples, correction types, failure patterns and outcomes. It helps separate model problems from workflow problems, data problems, prompt problems and validation problems.
Only then can the team make a sensible decision about whether a specialist model is worth it.
Do not start by claiming you own the intelligence. Build the mechanism that earns it.
A Simple Learning Loop Canvas
For one AI workflow, map:
- The task the AI performs
- The expected structured output
- The human review point
- The possible correction types
- Which corrections are reusable
- What validation checks apply
- Where the signal is stored
- How future performance will be measured
- When a specialist model would actually be justified
This turns "we need our own model" into a more useful conversation. Maybe you do. Maybe you need better retrieval, cleaner data, stronger rules, clearer review design or a proper evaluation set first.
The loop helps you find out without spending a fortune on the wrong kind of clever.
Design the Learning Loop First
- 01Pick one AI feature and map where the user reviews output
- 02Define what they can approve, edit, reject or escalate
- 03Decide how to capture why corrections happen
- 04Store the signal to improve prompts, rules, retrieval or evaluation
- 05Ask: after 1,000 uses, what will this product know that a competitor cannot see?